
编程竞赛: 在最近的编程竞赛中,o3 的表现可以与世界上顶尖的程序员相媲美
GPQA: 在 GPQA 数据集上,o3 的得分高达 87.7%(Gemini Flash 2 62%, o1 78%)
软件工程: o3 在 SWE-bench 验证集上的得分高达 71.7%,比 o1 高出 22.8 分。
数学难题:在 2024 年美国数学奥林匹克竞赛中只错了一道题,获得近 96.7% 的近乎完美得分。在 FrontierMath 2024-11-26 数据集上,o3 将准确率从 2% 提高到 25%。
ARC-AGI: 在 ARC 数据集上,o3 的得分在半私有测试集和公开验证集上分别达到了 87.5% 和 91.5%,sonnet10月22日的测试结果只有20%。
不是AGI(通用人工智能)
ARC-AGI 即抽象和推理语料库,是衡量 AI 获取新技能效率、评估其是否迈向通用智能的基准测试,o3获得了史无前例的高分远远超过其它大模型。
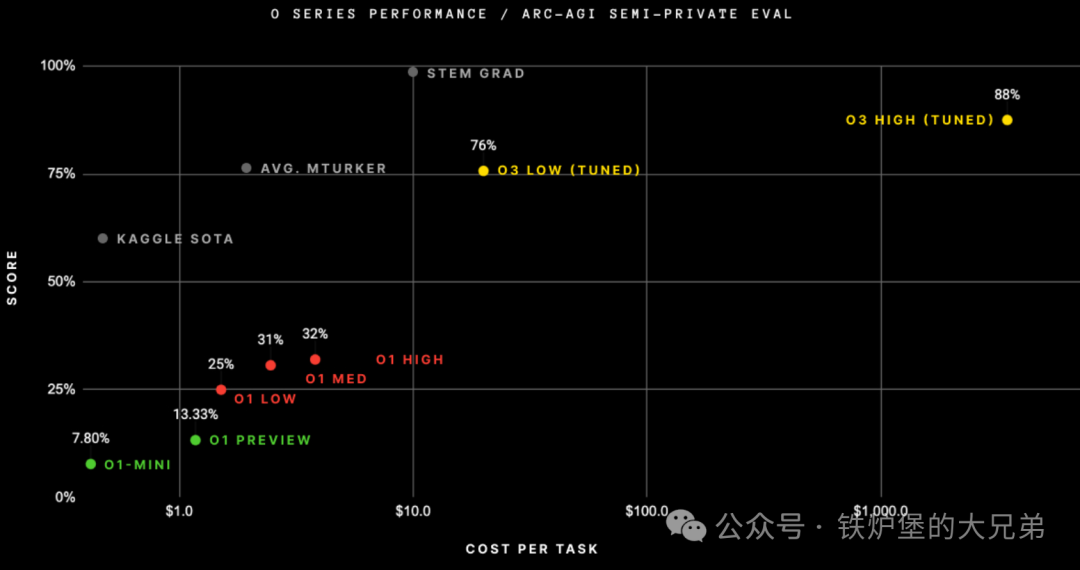
但它诞生于2019年,即将升级到 ARC-AGI-2,官方预测o3的得分可能会降低到30%以下,而人类在没有训练的情况下得分可以超过95%。虽然o3在许多高难度评测中取得了很好的成绩,但却无法解决一些在人类看起来很简单的问题,所以它仍然不是AGI。如果找到人类可以轻松解决而AI很难解决的问题变得非常困难的时候,就是AGI了,但现在显然不是。
OpenAI o3仍然是巨大的升级
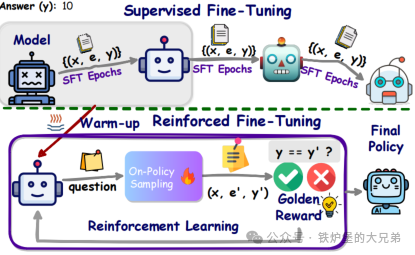
ARC-AGI 是专门设计来衡量对新事物适应性的基准,GPT-3得0分,GPT-4也是0分,GPT-4o得分接近5%。可见单纯的扩大模型参数和训练量无法提升模型的泛化能力,必须找到新的范式。为了适应新事物,人类通常需要两样东西:首先是知识,对模型来说是一组可重复使用的函数或程序来利用。大模型有足够多的知识。其次,需要在面对新任务时有重组知识的能力,对模型来说一个对新任务进行建模的程序,所谓程序合成。大模型长期以来一直缺乏这个功能,但o系列模型解决了这个问题。o3的核心机制应当也是RFT技术(Reinforcement Fine Tuning),是在token空间内的大模型引导的自然语言程序搜索和执行,模型搜索描述解决任务所需步骤所有可能的思想链(CoT),而且有一个评估模型对每一条链路进行评估反馈。这可能也是解决单个 ARC-AGI 任务最终会占用数千万个tokens并花费1000美元的原因。总而言之,o3 代表了一个重大的飞跃,修复了大模型范式的根本限制——无法重新组合知识——它是通过一种 LLM 引导的自然语言程序搜索来实现的。这不仅仅是渐进的进步,而是一个新的领域。
Scaling law远未结束
模型进步并未放缓,post train 阶段的 scaling law 要比预期更有效。o1 preview是9月12日,o1正式版是12月5日,o3是12月20日,模型进步不但显著而且速度快,所以IIya看好合成数据和post train。Pre-train 面临的瓶颈并非 scaling law 失效,而是缺乏数据。
结论:
模型进步是AI投资逻辑的核心,对应用和硬件都是。但边际上,o3对硬件的预期改变更大一些,毕竟模型进步如此之快是远超市场预期的,OpenAI距离AGI更近了一步,必然会坚定的投入;而其它距离OpenAI又更远了一些,追赶的空间又大了一些。不管是光模块龙头50份额能不能守得住,不管未来是ASIC和GPU蛋糕比例如何划分,在AI未来渗透率几十倍空间面前现阶段都不构成本质的利空。
本文链接:https://fsby.vip/chatgpt/915.html
chatgpt官网中文版登录chatgpt官网介绍chatgpt官网中chatgpt官网中文版下载手机版chatgpt中文下载手机版官网chatgpt官网中文版电脑版免费下载chatgpt美国官网chatgpt官网设置页面chatgpt官网怎么使用开源chatgpt官网中文电脑版







