
Again,思路还是比较正常的(补一句,并不意味着做起来简单)。“很早”的时候,就看到过AWS的一篇文章是先做一次思维链,再在思维链基础上去总结的方案,虽然我也不知道怎么去搜这篇文章了。。。
所以更多的,是给了大家一个具体的证明,就是用这种人工产生的数据或者说强化学习,还是可以接着把推理方面的性能往上提的。感觉总的传闻就是大家都在干这个。然后不知道是不是OpenAI为了融资必须先端一点什么出来。看他们youtube上的视频也搞得挺着急挺抽象的。
工程上肯定是有很多细节的。比如看他们提供的例子里面的思维链的部分
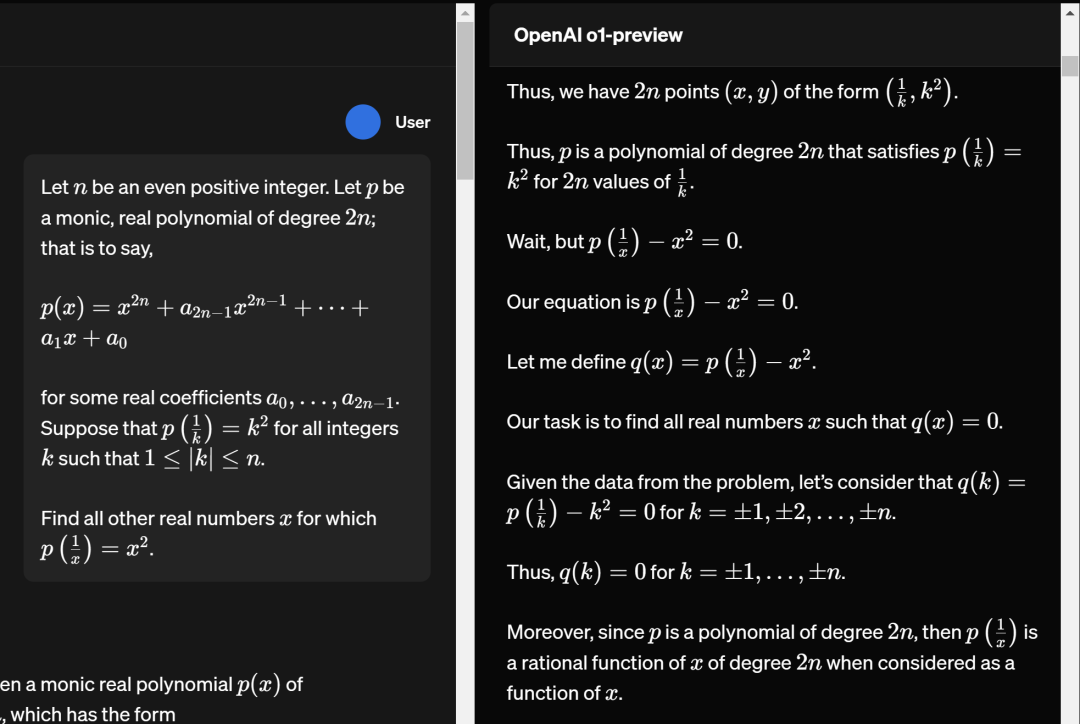
像"Wait, but..."这种语言,平时是不会在这些大模型的输出里的。一方面是因为,不管是互联网,还是数学书,都不太会有这种具体的思考过程。所以拿这些现成数据训练出来的模型也不太会讲这种话。他们似乎没具体讲是怎么训练产生思维链的模型的。不过他们明确说了思维链部分的输出不会给用户,因为给了的话,大家就都可以拿去训练了。
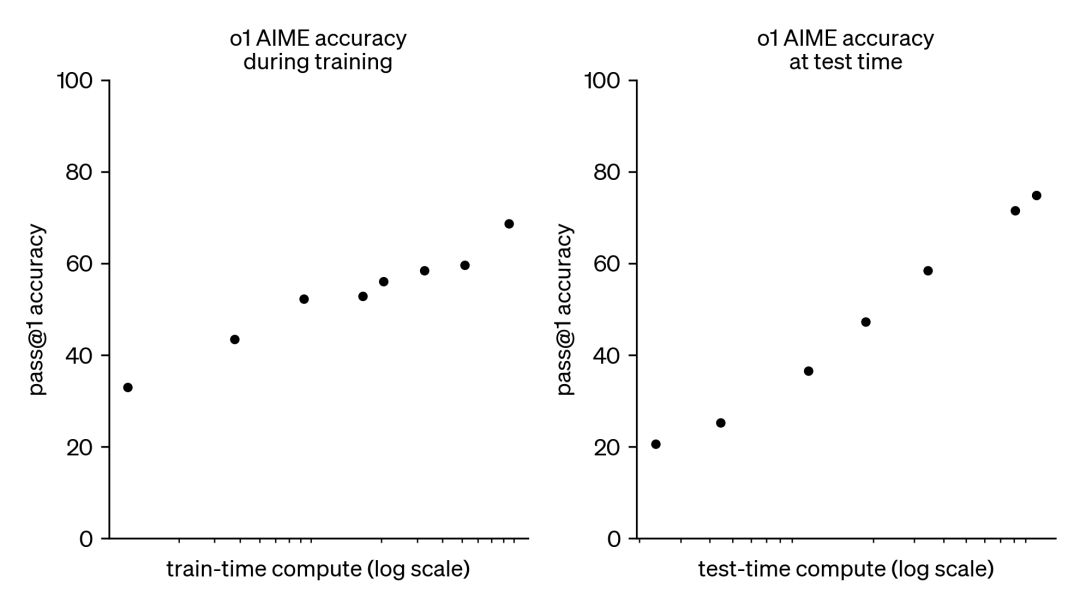
这张图是讲“强化学习”能带来的提升。横轴是对数,所以也不好说这条路能走多远。但应该不是每道题均匀的一个错误率,否则靠majority voting或者尝试直到通过可以更快的把成功率提上去。
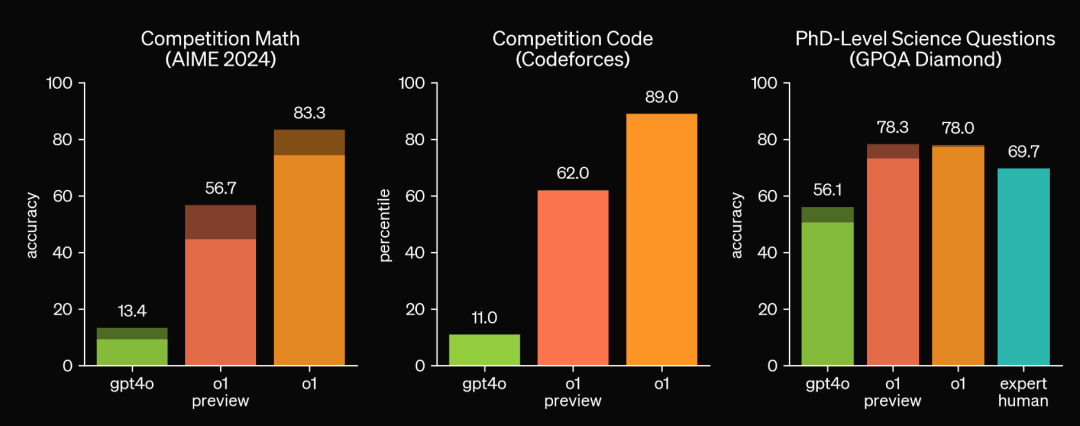
我们就假设o1应该是比o1 preview大一点的模型。挺有意思的,就是性能在科学GPQA已经收敛了(又到了可以吐槽不同学科竞赛含金量的时候了。不过认真地说,题目性质其实完全不一样,参见下文)。另一方面,我觉得science方面的问题是有点内在的错误率的。所以一直到现在,哪怕是物理这种已经比较数学的科学,实验一直是很被强调的一个方面,因为基本没有一个严格正确的推理。然后这种实验验证只有靠模型和现实世界的交互去实现。
不过我也不完全相信GPQA这个dataset的质量。比如他们文章里给的这个很量子信息的问题,就有一点怪怪的。大致上就是题干里和选项里的p不是同一个参数。然后我觉得也不太会说Kraus representation of the state,一般会说Kraus representation of the channel吧。

AIME的题目我去大概看了一眼,感觉还是比IMO或者国内竞赛之类容易不少的。不过与其说是在考验数学推理能力,不如说是在处理自然语言数学里的错误率问题。毕竟形式化的证明那边已经可以做IMO了。当然另一个差别是,o1 preview显然是在一个比较小的计算量下去做完题的,因为已经开放给用户用了,而google那边还是一个比较黑盒的状态。
大致就是这些吧。但感觉这种画饼式发布真的也是受够了。不过关于之前语音的模型,拖了很久貌似是因为语音上hallucination(或者说出错吧)的时候效果太恐怖了。平时文字版你出来些乱码或者什么的用户也就认了,语音聊天的时候冒出来的奇怪的东西真的可以被吓死。
本文链接:https://fsby.vip/chatgpt/96.html
chatgpt官网注册使用chatgptai官网chatgpt官网中文版能做什么chatgpt官网如何注册chatgpt官网介绍官网下载chatgpt教程chatgpt官网在哪打开官网chatgptchatgpt官网免费chatgpt 官网中文版







